Categorical Deep Q-Networks¶
Objective¶
The main objective of Categorical Deep Q-Networks is to learn the distribution of Q-values as unlike to other variants of Deep Q-Networks where the goal is is to approximate the expectations of the Q-values as closely as possible. In complicated environments, the Q-values can be stochastic and in that case, simply learning the expectation of Q-values will not be able to capture all the information needed (for eg. variance of the distribution) to make an optimal decision.
Distributional Bellman¶
The bellman equation can be adapted to this form as
where \(Z(s, a)\) (the value distribution) and \(R(s, a)\) (the reward distribution) are now probability distributions. The equality or similarity of two distributions can be effectivelyevaluated using the Kullback-Leibler(KL) - divergence or the cross-entropy loss.
The transition operator \(P^\pi : \mathcal{Z} \rightarrow \mathcal{Z}\) and the bellman operator \(\mathcal{T} : \mathcal{Z} \rightarrow \mathcal{Z}\) can be defined as
Algorithm Details¶
Parametric Distribution¶
Categorical DQN uses a discrete distribution parameterized by a set of supports/atoms (discrete values) to model the value distribution. This set of atoms is determined as
where \(N \in \mathbb{N}\) and \(V_{MAX}, V_{MIN} \in \mathbb{R}\) are the distribution parameters. The probability of each atom is modeled as
Action Selection¶
GenRL uses greedy action selection for categorical DQN wherein the action with the highest Q-values for all discrete regions is selected.
65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | def categorical_greedy_action(agent: DQN, state: torch.Tensor) -> torch.Tensor:
"""Greedy action selection for Categorical DQN
Args:
agent (:obj:`DQN`): The agent
state (:obj:`torch.Tensor`): Current state of the environment
Returns:
action (:obj:`torch.Tensor`): Action taken by the agent
"""
q_value_dist = agent.model(state.unsqueeze(0)).detach() # .numpy()
# We need to scale and discretise the Q-value distribution obtained above
q_value_dist = q_value_dist * torch.linspace(
agent.v_min, agent.v_max, agent.num_atoms
)
# Then we find the action with the highest Q-values for all discrete regions
# Current shape of the q_value_dist is [1, n_envs, action_dim, num_atoms]
# So we take the sum of all the individual atom q_values and then take argmax
# along action dim to get the optimal action. Since batch_size is 1 for this
# function, we squeeze the first dimension out.
action = torch.argmax(q_value_dist.sum(-1), axis=-1).squeeze(0)
return action
|
Experience Replay¶
Categorical DQN like other DQNs uses Replay Buffer like other off-policy algorithms. Whenever a transition \((s_t, a_t, r_t, s_{t+1})\) is encountered, it is stored into the replay buffer. Batches of these transitions are sampled while updating the network parameters. This helps in breaking the strong correlation between the updates that would have been present had the transitions been trained and discarded immediately after they are encountered and also helps to avoid the rapid forgetting of the possibly rare transitions that would be useful later on.
91 92 93 94 95 96 97 98 99 100 101 102 103 104 | def log(self, timestep: int) -> None:
"""Helper function to log
Sends useful parameters to the logger.
Args:
timestep (int): Current timestep of training
"""
self.logger.write(
{
"timestep": timestep,
"Episode": self.episodes,
**self.agent.get_logging_params(),
"Episode Reward": safe_mean(self.training_rewards),
|
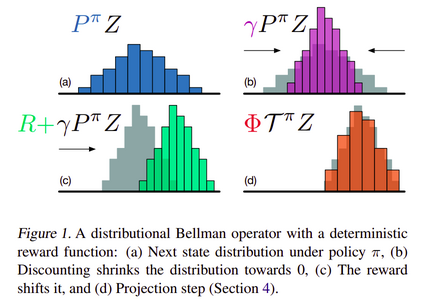
Projected Bellman Update¶
The sample bellman update \(\hat{\mathcal{T}}Z_\theta\) is projected onto the support of \(Z_\theta\) for the update as shown in the figure below. The bellman update for each atom \(j\) can be calculated as
and then it’s probability \(\mathcal{p_j}(x', \pi{x'})\) is distributed to the neighbours of the update. Here, \((x, a, r, x')\) is a sample transition. The \(i^{th}\) component of the projected update is calculated as
The loss is calculated using KL divergence (cross entropy loss). This is also known as the Bernoulli algorithm
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 | def categorical_q_target(
agent: DQN,
next_states: torch.Tensor,
rewards: torch.Tensor,
dones: torch.Tensor,
):
"""Projected Distribution of Q-values
Helper function for Categorical/Distributional DQN
Args:
agent (:obj:`DQN`): The agent
next_states (:obj:`torch.Tensor`): Next states being encountered by the agent
rewards (:obj:`torch.Tensor`): Rewards received by the agent
dones (:obj:`torch.Tensor`): Game over status of each environment
Returns:
target_q_values (object): Projected Q-value Distribution or Target Q Values
"""
delta_z = float(agent.v_max - agent.v_min) / (agent.num_atoms - 1)
support = torch.linspace(agent.v_min, agent.v_max, agent.num_atoms)
next_q_value_dist = agent.target_model(next_states) * support
next_actions = (
torch.argmax(next_q_value_dist.sum(-1), axis=-1).unsqueeze(-1).unsqueeze(-1)
)
next_actions = next_actions.expand(
agent.batch_size, agent.env.n_envs, 1, agent.num_atoms
)
next_q_values = next_q_value_dist.gather(2, next_actions).squeeze(2)
rewards = rewards.unsqueeze(-1).expand_as(next_q_values)
dones = dones.unsqueeze(-1).expand_as(next_q_values)
# Refer to the paper in section 4 for notation
Tz = rewards + (1 - dones) * 0.99 * support
Tz = Tz.clamp(min=agent.v_min, max=agent.v_max)
bz = (Tz - agent.v_min) / delta_z
l = bz.floor().long()
u = bz.ceil().long()
offset = (
torch.linspace(
0,
(agent.batch_size * agent.env.n_envs - 1) * agent.num_atoms,
agent.batch_size * agent.env.n_envs,
)
.long()
.view(agent.batch_size, agent.env.n_envs, 1)
.expand(agent.batch_size, agent.env.n_envs, agent.num_atoms)
)
target_q_values = torch.zeros(next_q_values.size())
target_q_values.view(-1).index_add_(
0,
(l + offset).view(-1),
(next_q_values * (u.float() - bz)).view(-1),
)
target_q_values.view(-1).index_add_(
0,
(u + offset).view(-1),
(next_q_values * (bz - l.float())).view(-1),
)
return target_q_values
|
Training through the API¶
from genrl.agents import CategoricalDQN
from genrl.environments import VectorEnv
from genrl.trainers import OffPolicyTrainer
env = VectorEnv("CartPole-v0")
agent = CategoricalDQN("mlp", env)
trainer = OffPolicyTrainer(agent, env, max_timesteps=20000)
trainer.train()
trainer.evaluate()